

UseRogue Secures Your Data
Our models use your data for better results but don’t expose your data
Table of contents
At UseRogue.com we care a lot about customer feedback and questions and the one we hear a lot “is my proprietary data protect, how does that work?”
A good rule is that if more than one customer asks the same question, then you need to proactively answer it, so here goes:
As a government contractor, you may be familiar with Generative Pre-Trained Transformer (GPT), a type of Large Language Models (LLM) used for natural language processing (NLP) tasks such as text generation and summarization. LLMs are powerful models that use a large training dataset to learn the complexities of natural language, and GPTs are no exception. However, once the models are trained (before anyone actually uses them) they are finished learning, at that point they do not retain additional data. This post will discuss how UseRogue is tuned and tailored to be better than an general GPT but does not expose your data to your competitors or even give them the benefit of your content.
So then how does it work?
Without diving into the intricacies of Role-based access control (RBAC) Vector Data Embeddings, and Reinforcement Learning with Human Feedback (RLHF), here’s the bottom line:
Users of UseRogue.com upload or generate their content on the platform. That data is saved in a private database, which includes your own context data. When you use any of the AI-powered tools, you send a request (prompt) to the model with (context) data saved in your database. You then get a custom return thanks to the context that is passed from your database and the prompts we built into the platform. You are the only beneficiary of your data because the model does not learn, and all of your data is private to you.
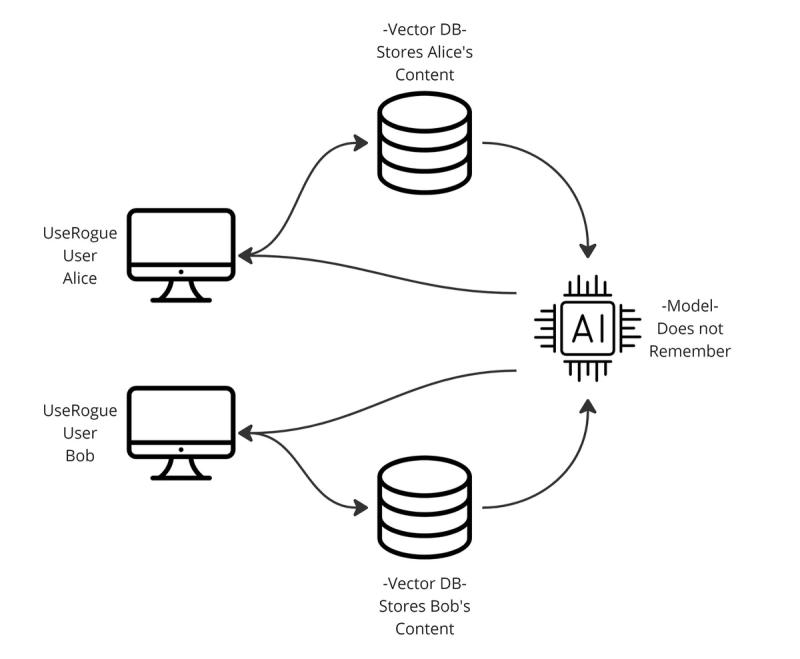
The Model Does Not Retain Your Sensitive Data
When a user queries the LLM for generation, the query is not stored in the model and no additional information is added to the model from the query. Despite this, GPT can still be used in applications such as text generation and summarization without needing to store any user data. Large language models use a technique called transfer learning to generate text based on a prompt without learning from the prompt. This involves pre-training the model on a large dataset and then fine-tuning it on a smaller dataset, allowing the model to quickly learn the patterns and features of the smaller dataset without having to learn from scratch. We fine tuned UseRogue with examples of the kinds of documents we wanted it to output and then built Reinforcement Learning with Human Feedback into the workflow, so as you edit your documents, the model provides you with better outputs.
UseRogue Embeds Data into a Protected Unstructured Database
UseRogue.com allows users to embed their data into an unstructured database unique to their organization and protected from any other users. Using Rogue Embeds, GPT can store data securely in an unstructured database. This means that the data is not visible to any other users and remains under tight security protocols. The model's machine learning capabilities are enhanced as it is able to perform sophisticated tasks such as nearest neighbor search and semantic similarity without having access to the user's private information. This ensures that all of the user’s sensitive information remains safe while still allowing GPT to learn from their data. In addition, this method allows for faster query processing as there is no need to wait on external servers or transfer large amounts of data over networks when performing queries.
It Does Make Your Data More Valuable
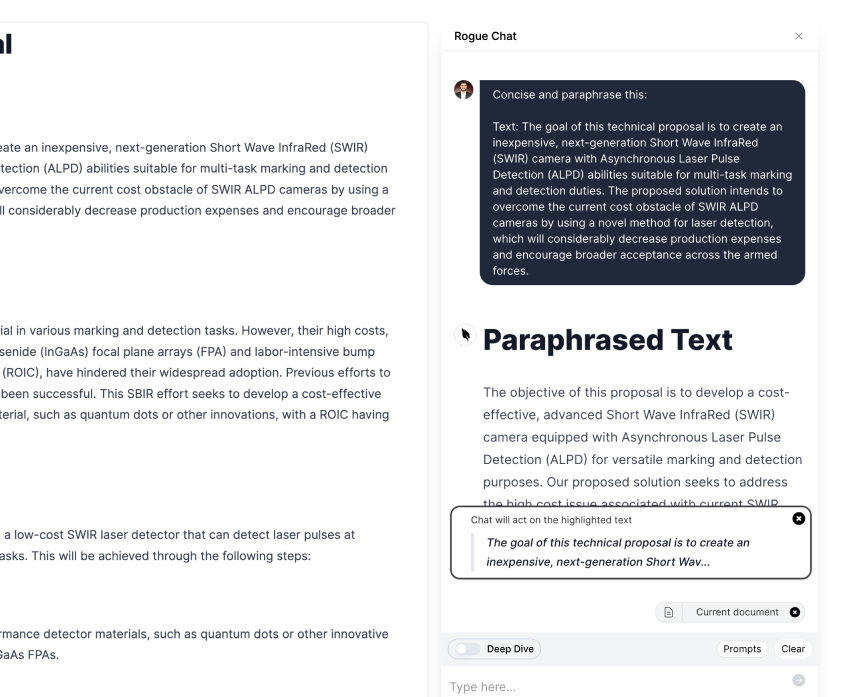
UseRogue does not put your data at risk of being seen by others, but the technology does make it more valuable. Embedding your data into a vector database allows you to access all of the related information from one source. Vector databases are a type of database that stores data in a vector format. This means that the data is stored as a set of numerical values, rather than as text or other types of data. Vector databases are used to store and process large amounts of data quickly and efficiently. They are often used in machine learning applications, where the data needs to be processed quickly and accurately. Vector databases are also used in natural language processing, where the data needs to be represented in a numerical format in order to be processed by a machine learning algorithm. This makes it easier for you to analyze and understand the relationships between different sets of data. Additionally, this structure enables the LLM to quickly process large amounts of your historic content very quickly, allowing it to uncover patterns and correlations in real-time. Instead of searching using keywords with ctrl+F, you can now just ask a question or select text, and the model will give you similar content from your data. The model acts like a private assistant for your private data repository.
Bottom Line
LLMs, like the one powering UseRogue do not take or store user data, but can still be used as we do, in concert with your private data to produce high-quality, relevant, tailored content. UseRogue is built by GOVCON veterans, we know how important your proprietary information is to you.

Sign up for Rogue today!
Get started with Rogue and experience the best proposal writing tool in the industry.