

What is Model Training and Tuning Anyway?
You hear a lot about training, a bit less about tuning, but what does it all mean?
Table of contents
Model training and tuning are two essential parts of machine learning that involve teaching a model to recognize patterns, relationships, and dependencies in data. While they are two distinct processes, they are both necessary for achieving a successful model. In this blog post, we'll discuss what model training and tuning are, how they differ, and why it's important to invest in pre-trained model tuning. Think of these two concepts as the difference between teaching a child to read and write, and teaching a child to read write poetry, the former takes a lot more time and effort than the latter.
Introduction
Model training and tuning are two distinct processes that are often used together in order to improve a model's performance. Model training involves the process of teaching a model to recognize patterns, relationships, and dependencies in data. It is accomplished by feeding the model large datasets. Model tuning is a process of fine-tuning a model's parameters in order to improve its performance. The tuning process does not require additional data and involves adjusting existing parameters to improve the performance of the model.
It is important to differentiate between model training and tuning. Model training requires the model to learn from data in order to generate predictions. This process can take considerable time, especially for large language models (LLMs). Model tuning, on the other hand, does not require additional data and involves adjusting parameters in order to optimize the performance of the model.
Training Large Language Models
When training a large language model, it is essential to have access to powerful computing resources. This includes both hardware, such as GPU's and TPU's, and software tools such as distributed training frameworks like Apache Spark. Additionally, these models require vast amounts of data for training, which can be difficult or expensive to obtain. For this reason, many organizations choose to use pre-trained models or use public datasets instead of creating their own from scratch. Despite the challenges that come with building an LLM from scratch, the rewards are immense; properly trained large language models can provide unparalleled accuracy in natural language processing tasks.
Training an LLM is similar to teaching a child how to read and write. To teach a child, you need to provide them with lots of reading and writing examples that allow them to connect words with images and concepts. This process takes years for humans but can be sped up for artificial intelligence models. Just like teaching a child, the more data you expose an LLM to during the training process, the better it will be at recognizing patterns in data later on. The larger the dataset used for model training, the more accurate your predictions are likely to be. By using large datasets as part of model training, language models can learn from millions of interactions from different sources (including text, audio recordings or videos) in order to recognize patterns in unseen data rather than just relying on pre-defined rulesets or subsets of labeled information which may not accurately reflect reality.
Pre-trained Model Tuning
Pre-trained model tuning, like teaching Shakespeare to a child, requires an understanding of basic concepts before more complex ideas can be taught. The pre-trained model already understands the basics and has been trained on certain datasets but needs to be tuned in order to optimize its performance for a particular task or application. Tuning involves adjusting the parameters of the model such as learning rate, regularization strength, and optimization algorithm. This ensures that the model is able to effectively learn and use data relevant to its intended purpose. Pre-trained model tuning can improve the performance of a language model by fine-tuning the weights that are already present in the pre-trained model. If a child knows how to read, you don't have to teach them how to read again in order to teach them Shakespeare. You do have to show them Shakespeare, ask them to write Shakespeare, and correct their work when they make mistakes - the same is true with model tuning. Tuning a pre-trained model is much faster and less intensive, but it does require adept system engineering to make the reinforcement process user-friendly.
Bonus: What's a GPU Hour?
GPU days or GPU hours are commonly used in deep learning to measure the amount of time taken to train a model on a GPU (Graphics Processing Unit). This specialized hardware is designed to increase the speed of computationally demanding tasks, including 3D graphics rendering, image and video processing, and deep learning. Specifically, one GPU day is equal to training a deep learning model for 24 hours on one GPU, while a single GPU hour is equal to training a deep learning model for one hour on one GPU. The amount of time taken for training a deep learning model is dependent on the size and complexity of the model, the data it is being trained with, and the type of GPU used. GPU days or GPU hours are often used to compare the training times of different deep learning models, as well as measure the performance of different GPUs. It is typically noted that GPUs are much faster than CPUs when it comes to deep learning, thus reducing the amount of time needed to train a model.
For instance, a recent cutting-edge model called LLaMA 65B (developed by Facebook Research) required just over 1,022,362 GPU hours using 2048 A100 GPUs. That means ~500 hours per GPU. What is an A100, you ask? It's an industry-leading GPU made by Nvidia that runs about $15,000 each, so we're talking about $30,000,000 worth of just GPU cards, not counting the actual computers that house them, the power, etc.
Conclusion
Model training and tuning are two essential parts of machine learning that involve teaching a model to recognize patterns, relationships, and dependencies in data. While they are two distinct processes, they are both necessary for achieving a successful model. Pre-trained model tuning offers several benefits, including improved accuracy and better performance when compared to untuned models. Companies willing to invest in pre-trained model tuning are likely to see better results than those that do not invest in this process. The time and resources spent on pre-trained model tuning will pay off in the long run as the model learns more complex concepts and produces better results.
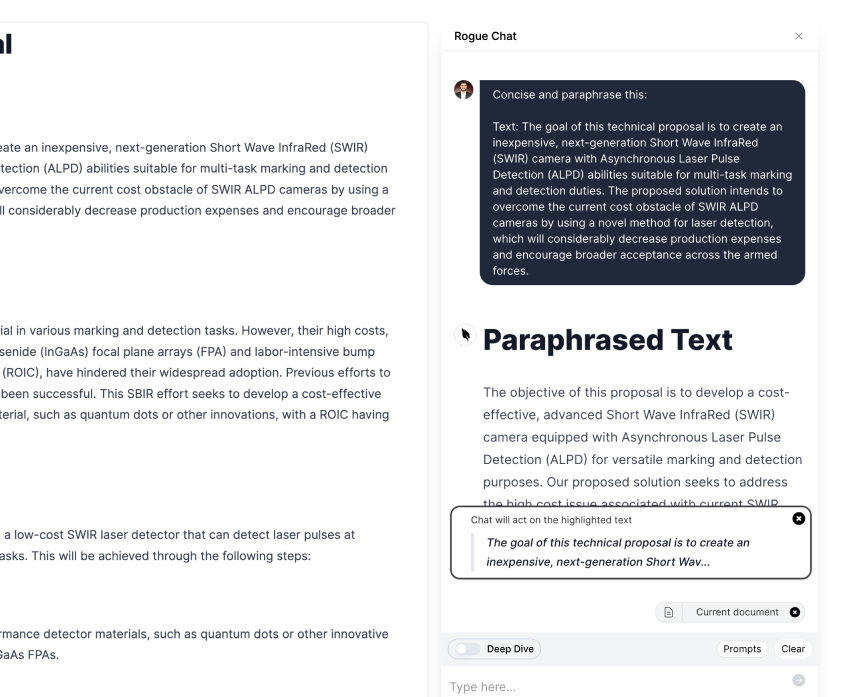

Sign up for Rogue today!
Get started with Rogue and experience the best proposal writing tool in the industry.