

Module 1.c: Some Words of Caution
©️You are free to adapt and reuse provided (1) that you provide attribution and link to the original work, and (2) you share alike. This course and all of its contents are the property of UseRogue.com and are offered under the Creative Commons BY-SA 4.0 License.
I. BLUF
Generative Pretrained Transformers (GPTs) are a new type of artificial intelligence (AI) that can transform various sectors, including government contracting. These AI models can understand and generate human-like text, making them useful for tasks such as drafting emails and writing reports.
But, (and this is a fairly big but) while GPTs offer immense potential, it's critical for users, especially government contractors, to understand their limitations and the potential risks they pose. So, lets discusses some important points of caution when using GPTs.
II. Understanding GPTs: What You Need to Know
Before we delve into the cautionary aspects, let's briefly discuss what GPTs are. These models are "trained" on a vast amount of data before they're made available for public use. Once trained, they do not "learn" or adapt based on new user inputs. Some of them are "tuned", but we're not going down that rabbit hole here. Bottom line, their knowledge is limited to the data they were fed during training, which typically encompasses a vast portion of the open internet.
The important thing to remember is that despite their extensive training, GPTs are not encyclopedias and should not be treated as such. They can assist with tasks requiring text generation or language translation but should not be relied upon for generating accurate factual information.
III. Cautionary Words When Using GPTs
GPT Hallucinations
The first word of caution when using GPTs is to be wary of what is known as 'model hallucinations.' This phenomenon occurs when GPTs generate incorrect or entirely fabricated information. It's essential to verify the information generated by these models before using it in any critical decision-making process.
Causes
- Training Data: GPT models are trained on vast amounts of data from the internet, which include both factual and fictional information. The models often cannot distinguish between the two.
- Lack of Contextual Understanding: GPT models generate text based on patterns and statistical relationships between words and phrases, but they don't understand context in the same way humans do.
- Information Limitations: GPT models can only use the information they were trained on and cannot access real-time data or updates.
Implications
While GPT hallucinations can sometimes lead to creative and novel outputs, they can also result in misinformation or generation of inappropriate content. It's important to use these models responsibly, with an understanding of their limitations.
Mitigations
The major model producers like Google and OpenAI are actively researching methods to reduce such hallucinations and improve the factual accuracy of GPT model outputs. This includes refining training processes, developing external fact-checking systems, and allowing users to customize AI behavior within broad bounds.
GPT's Temporally Limited Knowledge
GPT models have what is called 'temporally limited knowledge'. This is because these models are trained on a snapshot of the internet and do not have the ability to access or know any information beyond their training cut-off.
Reasons for Temporally Limited Knowledge
- Static Training Data: GPT models learn from a fixed dataset that is collected at a specific point in time. They do not have the capability to update their knowledge base with new information beyond this point.
- No Real-Time Access: Unlike humans, some GPT models cannot browse the internet or access real-time information. They generate responses based on patterns they've learned from the data they were trained on. Exceptions include Bard
- Lack of Contextual Understanding: GPT models do not understand context in the same way humans do. They cannot comprehend the concept of time and its progression.
Implications
This temporal limitation means that GPT models cannot provide information on events or developments that have happened after their training data cut-off. For example, a GPT model trained on data up to 2020 would not know about events or information from 2021.
Mitigations
While GPT models cannot update their knowledge autonomously, new iterations of these models can be trained on more recent data to incorporate newer information. However, this is a manual and resource-intensive process.
IV. Security Concerns with GPTs
Input and Output Monitoring on Generative Models
Government contractors deal with sensitive information that often has implications on national security. Therefore, understanding how GPT providers handle data becomes critical. Companies like OpenAI record user inputs and outputs for various reasons, including improving their models and ensuring compliance with laws. Input and output monitoring is a critical part of ensuring the safe and responsible use of AI models like ChatGPT, but as Samsung employees learned, you need to avoid putting certain data into these interfaces.
Input Monitoring
Input monitoring refers to checking the prompts or inputs provided by users to the ChatGPT model. It is crucial to:
- Prevent Misuse: By monitoring inputs, inappropriate or harmful prompts can be identified and blocked, preventing the model from generating potentially harmful outputs.
- Ensure User Safety: It helps in detecting and mitigating risks to user safety, such as attempts to extract personal information or engage in illegal activities.
Output Monitoring
Output monitoring involves assessing the responses generated by the ChatGPT model. This is important to:
- Avoid Harmful Outputs: Even with harmless inputs, AI models might generate harmful or inappropriate outputs due to biases in training data or other factors. Monitoring helps in identifying and mitigating such issues.
- Improve Accuracy: By verifying the model's outputs, inaccuracies and errors can be identified and used to improve the model's performance.
- Ensure Compliance: It ensures that the model's outputs are in line with ethical guidelines, policies, and regulations.
Implementations
OpenAI implements a two-step process to reduce harmful and untruthful outputs, which includes pre-training and fine-tuning with human reviewers. They also utilize reinforcement learning from human feedback (RLHF) to improve the behavior of models like ChatGPT.
Challenges
While input and output monitoring is essential, it also brings challenges such as ensuring user privacy, handling the vast amount of data, and dealing with the complexity of language, context, and cultural nuances. Additionally, there's a balance to be struck between moderating content and allowing freedom of expression.
Given this scenario, you should exercise due caution when inputting proprietary or sensitive information into a GPT. There's always a risk that such information could be inadvertently exposed or misused.
V. The Need for Editing GPT Outputs
GPT outputs typically have a certain form and shape that can often make them recognizable as machine-generated text. While these outputs may be grammatically correct and coherent, they may lack the human touch or specific nuances that make text engaging and relatable.
Thus, it becomes necessary to edit GPT outputs before using them in formal communications or reports. This editing helps ensure that the generated text doesn't appear blatantly machine-generated and aligns with your specific communication style and requirements.
We'll discuss this more in the next section, but the bottom line up front here is that, as generated content become even more mainstream, more people will have innate GPT detectors. In some cases that may be fine, but in most cases you don't really want your readers to think that you didn't take the time to write what they are reading, so at least take the time to edit what the model generates.
VI. Don't be Scared
While this article might seem like a litany of cautionary tales, it is not meant to scare you away from using GPTs or other generative models. These models are powerful tools that can significantly enhance productivity and efficiency when used responsibly and effectively.
Recapping the key points: remember that GPTs do not learn post-training; they might produce incorrect or fabricated information; their knowledge is temporally limited; sensitive information should be handled cautiously; and their outputs often need editing.
Despite these words of caution, remember that generative models like GPTs are excellent tools that can greatly assist you in your tasks as a government contractor. Just remember to exercise diligence and responsibility when using them, and you'll be well on your way to leveraging the power of AI!
VIII. Practical Exercise
- Check out this cautionary tale from Samsung
- Lets head over to Anthropic and sign up for Claude
- Now input this prompt sequence:
- write a 500-word comprehensive company capabilities statement, focus on explaining the services
- your company provides business, financial, and program management services to the Department of [insert agency here]
- write a 500-word comprehensive company capabilities statement, focus on explaining the services
- if it puts in names (even though you told it not to) try this: rewrite but replace any mention of the company with "[insert company here]" and replace any customer names with "[insert department here]”
- You sanitized your inputs, so you didn’t give anything away to the model, and you cleaned up its outputs, so it will be easy to copy-paste-find-replace and have a well-written capes statement that you didn’t have to write
- Now try to modify it and make your own, and share your prompts in the group
- Give feedback below
GovCon GPT Masterclass
31 lessons
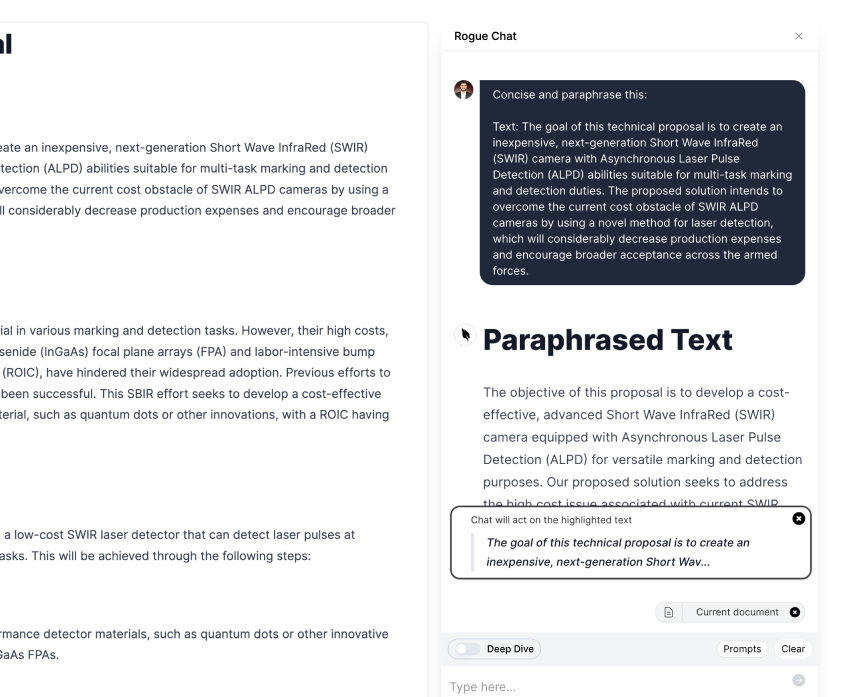

Sign up for Rogue today!
Get started with Rogue and experience the best proposal writing tool in the industry.